
K-Means 算法实现消费者聚类
Published:
本实验自行实现了 K-Means 算法和聚类性能指标评估函数(SSE、SC、CH等),并对消费者数据集 Mall_Customers.csv 进行聚类分析。
scikit-learn 中的 K-Means 库函数参见 sklearn.cluster.KMeans.
基础理论
K-Means 聚类算法是一种动态聚类方法,使用误差平方和准则作为聚类准则,寻求使
\[SSE=\sum_{i=1}^K\sum_{X\in \omega_i}||X-\mu_i||^2\]最小的聚类结果,其中 \(\mu_i\) 表示 \(\omega_i\) 类的样本均值,亦即聚类中心。
该算法的具体步骤如下:
- 从输入样本集中选取 K 个样本作为初始聚类中心;
- 计算每个样本到各聚类中心的距离,并将其划分到距离最近的聚类中心所在的类;
- 更新每个类的聚类中心;
- 若各聚类中心相比更新前没有发生变化,算法结束,否则返回第 2 步。
聚类性能评价指标
误差平方和(SSE)是一个常用的聚类性能评价指标。其他常用的评估指标还有轮廓系数、Calinski-Harabasz 指数等。
轮廓系数(SC):对于每个样本点 \(i\),定义 \(a_i\) 为 \(i\) 与同一类内其他样本点的平均距离,\(b_i\) 为 \(i\) 与其他类中样本点的最小平均距离,则样本点 \(i\) 的轮廓系数为
\[s_i=\frac{b_i−a_i}{\max(a_i,b_i)}\]整个数据集的轮廓系数(即 SC)为所有样本点轮廓系数的平均值。轮廓系数的取值范围为 [−1,1],越接近 1 表示聚类效果越好。
Calinski-Harabasz 指数(CH):计算公式为
\[CH=\frac{SS_B/(K-1)}{SS_W/(n-K)}\]其中 \(K\) 是聚类数,\(n\) 是样本点的个数,\(SS_W\) 是簇内平方和,即 SSE,\(SS_B\) 是簇间平方和,由如下公式计算:
\[SS_B=\sum_{i=1}^Kn_i||\mu_i-\mu||^2\]其中 \(n_i\) 是第 \(i\) 类中样本点的个数,\(\mu_i\) 是第 \(i\) 类的中心,\(\mu\) 是整个样本集的中心。一般而言,CH 越大,表示聚类结果越好。
算法核心代码实现
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
class KMeans:
def __init__(self, K, data, seed="random", initialize_method="random"):
self.K = K # 聚类数
self.data = data # 待处理样本集
self.seed = seed # 随机初始化聚类中心的种子,若为"random"则随机初始化
self.initialize_method = initialize_method # 初始化聚类中心的方法,"random"->随机初始化,"maxmin"->最大最小距离法初始化
self.centers = np.zeros((K, data.shape[1])) # 聚类中心
self.labels = np.zeros(data.shape[0]) # 样本标签
self.distances = np.zeros((data.shape[0], K)) # 样本到聚类中心的距离
def fit(self):
"""算法主过程"""
if self.initialize_method == "maxmin":
self.init_centers_maxmin()
else:
self.init_centers_random()
while True:
self.update_labels()
centers = self.centers.copy()
self.update_centers()
if np.allclose(centers, self.centers): # 若聚类中心不再变化,则停止迭代
break
def init_centers_random(self):
"""随机初始化聚类中心"""
if self.seed != "random":
np.random.seed(self.seed)
self.centers = self.data[np.random.choice(self.data.shape[0], self.K, replace=False)]
def init_centers_maxmin(self):
"""最大最小距离法初始化聚类中心"""
self.centers[0] = np.mean(self.data, axis=0)
for i in range(1, self.K):
self.centers[i] = self.data[np.argmax(np.min(cdist(self.data, self.centers[:i]), axis=1))]
def update_labels(self):
"""更新样本标签"""
self.distances = cdist(self.data, self.centers) # 计算样本到聚类中心的欧式距离
self.labels = np.argmin(self.distances, axis=1)
self.inertia_= np.sum(np.min(self.distances, axis=1)) # 计算损失函数SSE
def update_centers(self):
"""更新聚类中心"""
for i in range(self.K):
self.centers[i] = np.mean(self.data[self.labels == i], axis=0)
def show(self):
"""可视化聚类结果,支持二维和三维数据集"""
if self.data.shape[1] == 2:
ax = plt.subplot(111)
elif self.data.shape[1] == 3:
ax = plt.subplot(111, projection='3d')
for i in range(self.K):
ax.scatter(*self.data[self.labels == i].T, label=i, color=f'C{i}', alpha=0.5)
plt.legend()
plt.show()
def metric(self, *args, type:str='sse', **kwargs):
"""算法性能评估函数"""
type = type.lower()
if type == 'sse':
return self.inertia_
elif type == 'ch':
SSB = SSW = 0
for k in range(self.K):
cluster_k = self.data[self.labels == k]
mean_k = np.mean(cluster_k, axis=0)
SSB += len(cluster_k) * np.sum((mean_k - np.mean(self.data, axis=0)) ** 2)
SSW += np.sum((cluster_k - mean_k) ** 2)
return SSB * (self.data.shape[0] - self.K) / (SSW * (self.K - 1))
elif type == 'sc':
s = np.zeros(self.data.shape[0])
for i in range(self.data.shape[0]):
a = np.mean(cdist(self.data[self.labels == self.labels[i]], [self.data[i]]))
b = np.min([np.mean(cdist(self.data[self.labels == j], [self.data[i]])) for j in range(self.K) if j != self.labels[i]])
s[i] = (b - a) / max(a,b)
return np.mean(s)
算法效果测试
使用sklearn.datasets中的make_blobs生成聚类数据集。使用随机初始化聚类中心,算法对一个四类二维数据集聚类的效果如下:
from sklearn.datasets import make_blobs
data, _ = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
kmeans = KMeans(4, data, initialize_method="random")
kmeans.fit()
kmeans.show()
print("SC =", kmeans.metric(type='sc'), "CH =", kmeans.metric(type='ch'))
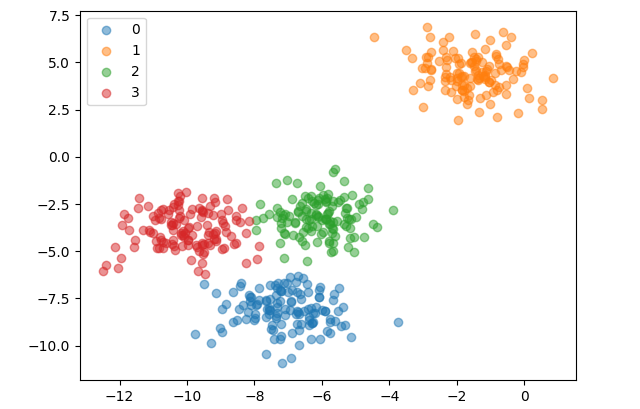
SC = 0.6533114915704118 CH = 2704.4858735121097
使用最大最小距离法初始化聚类中心,算法对一个四类三维数据集聚类的效果如下:
data, _ = make_blobs(n_samples=500, n_features=3, centers=4, random_state=1)
kmeans = KMeans(4, data, initialize_method="maxmin")
kmeans.fit()
kmeans.show()
print("SC =", kmeans.metric(type='sc'), "CH =", kmeans.metric(type='ch'))
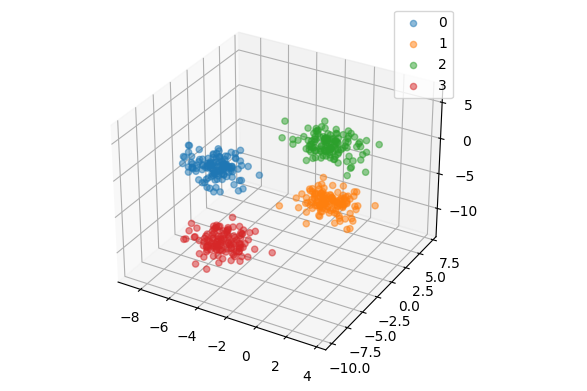
SC = 0.7483429748063692 CH = 2980.2065104935014
可见算法具有较好的聚类效果。
数据预处理
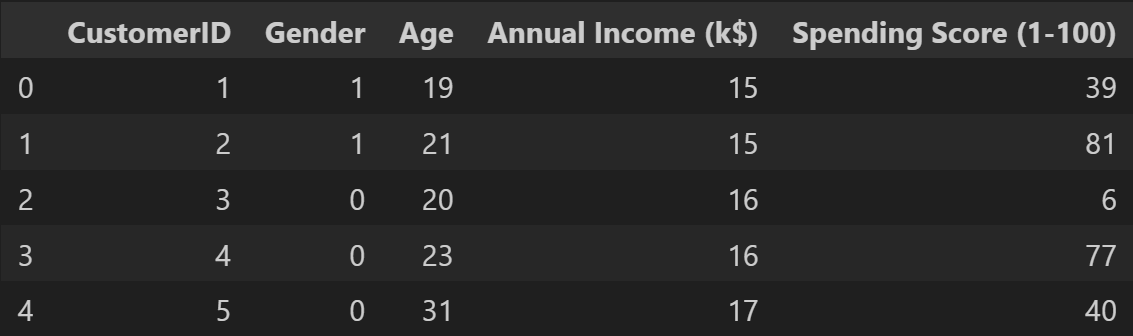
从Mall_Customers.csv中导入样本集,对性别属性进行0-1化处理。
import pandas as pd
from sklearn import metrics
data = pd.read_csv('Mall_Customers.csv')
data = data.assign(Gender=data.Gender.map({'Male':1, 'Female':0}))
data.head()
import seaborn as sns
sns.heatmap(data.corr('kendall'),annot=True)
sns.pairplot(data)
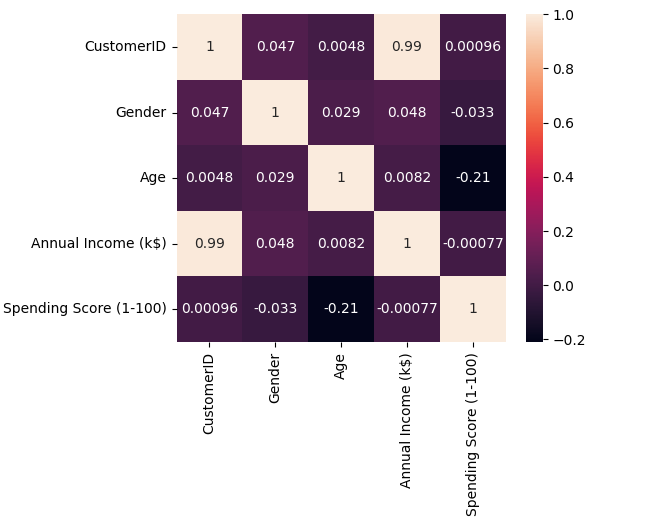
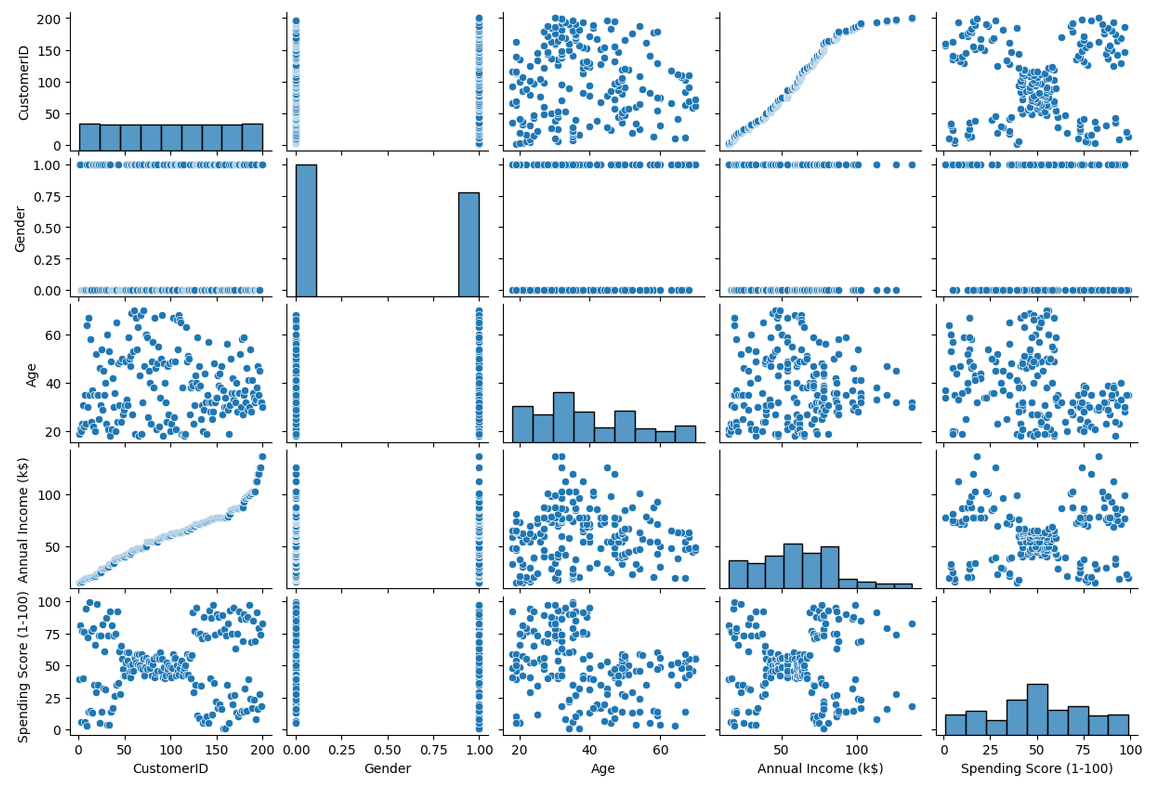
可见性别与其他属性数据的分布无关,且Annual income (k$)和 CustomerID呈正相关,选择后三个属性进行聚类。
data = data.iloc[:, 2:].values
选定最佳 K 值
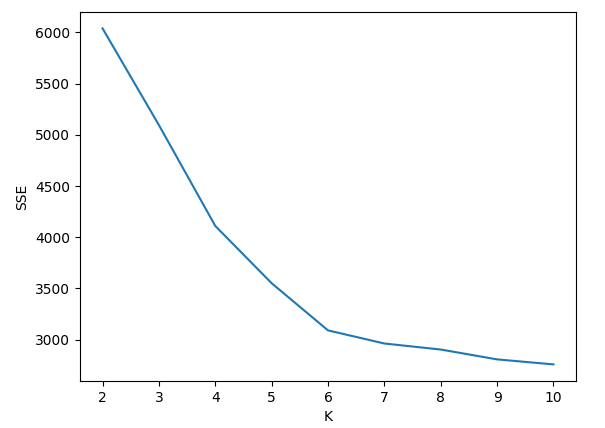
一般而言,SSE 随 K 的增加而单调减少,且随 K 的增加减少程度变缓。利用这个特点,可以选择 SSE-K 曲线上的“拐点”所对应的 K 值作为真实类别数的估计。
使用随机初始化聚类中心,且固定随机数种子为 10,对不同的 K,聚类效果如下。
fig = plt.figure(figsize=(15, 15))
inertia = []
for i in range(2, 11):
kmeans = KMeans(i, data, seed=10)
kmeans.fit()
inertia.append(kmeans.inertia_)
ax = fig.add_subplot(3, 3, i - 1, projection='3d')
for j in range(i):
ax.scatter(*kmeans.data[kmeans.labels == j].T, label=j, color=f'C{j}', alpha=0.5)
ax.set_title(f'K = {i}')
plt.legend()
plt.show()
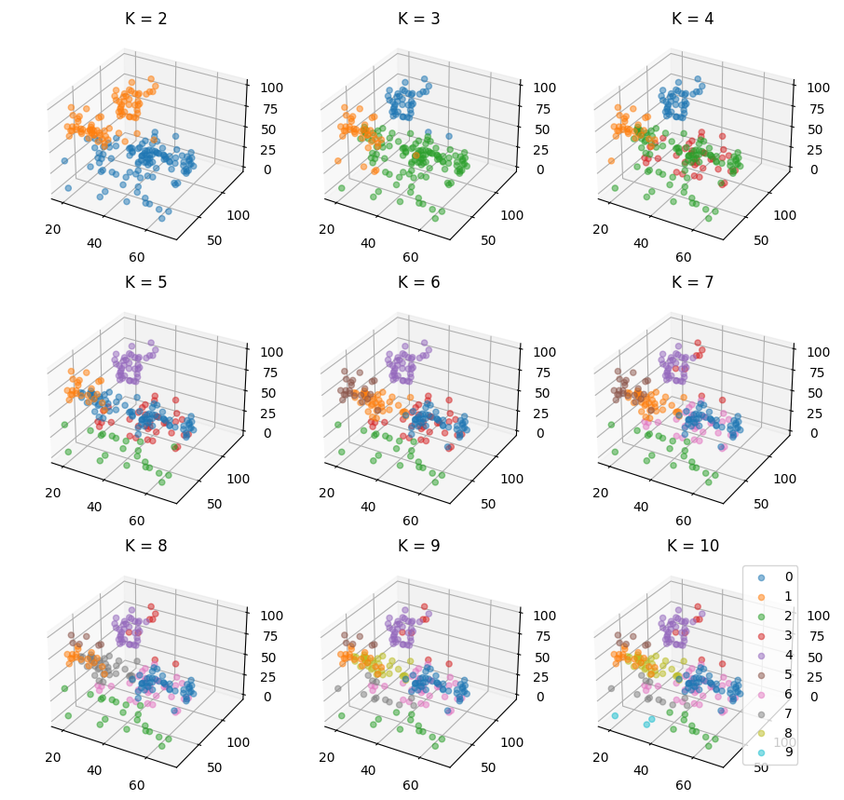
绘出 SSE-K 曲线如下,可见曲线的拐点出现在 K=6。因此选取 K=6 作为真实类别数的估计。
plt.plot(range(2, 11), inertia)
plt.xlabel('K')
plt.ylabel('SSE')
plt.show()
性能评估与总结
选定 K = 6,分别使用sklearn.metrics中的评估指数函数和自定义类中的评估指数函数对聚类结果进行评估。
from sklearn import metrics
kmeans = KMeans(6, data, seed=10)
kmeans.fit()
print("库函数: SC =", metrics.silhouette_score(data, kmeans.labels), "CH =", metrics.calinski_harabasz_score(data, kmeans.labels))
print("自定义: SC =", kmeans.metric(type='sc'), " CH =", kmeans.metric(type='ch'))
库函数: SC = 0.45097989004959005 CH = 166.59041626979342
自定义: SC = 0.4672195001984971 CH = 166.59041626979342
可见算法取得了较好的聚类效果。
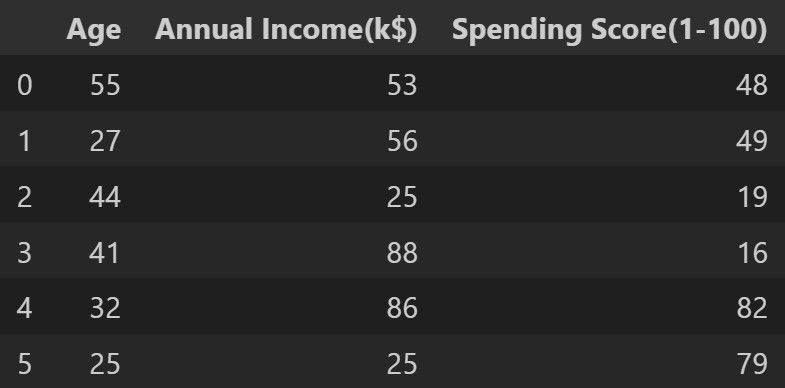
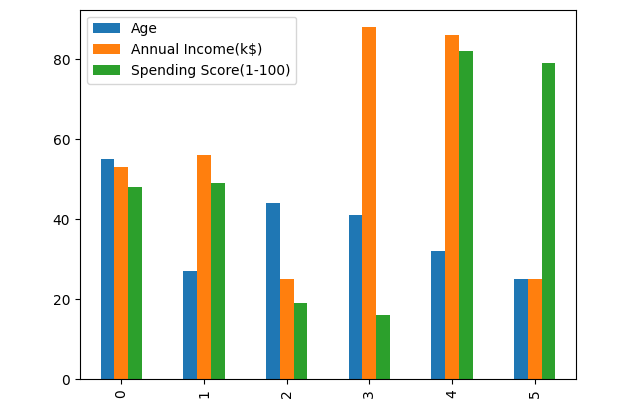
各类的聚类中心样本的年龄、年收入、消费分数如下:
result = pd.DataFrame(kmeans.centers, columns=['Age','Annual Income(k$)','Spending Score(1-100)'])
result.plot(kind='bar')
print(result)
plt.show()
附录
其他可用作聚类练习的数据集: abalone、concrete_data、housing 等。
参考资料:汪增福《模式识别》,P197-203。